A scientist, a musician, and a normal student discovering their aspirations. I can usually be found at my discord server. Head over if you want to receive updates when I post, or have a question, or even just simply want to be part of a group.
See below for my unadulterated thoughts, or head to archives for a list of all of them.
I would like to extend a token of thanks to several people, without whom this website would not exist:
Jocelyn Baker, for providing all the resources that allowed me to build this;
Morgan Arnold, for reigniting my desire to build a website; and
Rashid Al-Abri, for being a wonderful head of Hack Club and reccommending the use of Visual Studio Code.
Following the success of the Standard Horizontal Inertial Theory (SHIT),
we aim to uncover another piece of hidden truth of the world.
Today, we present to you,
the Cruel and Biased Theory (CBT).
Introduction
The world is a cruel and unfair place.
Different people will innately be offered different opportunities,
and some will always be dealt a bad hand in life.
No matter how much we preach about equality,
it is impossible to completely eliminate all these predetermined factors.
Now, a slight change in topic.
The fundamental assumption of statistical mechanics state that
the every microstate is equally likely to be found,
and each of these arrangements have a fair and equal chance of appearing.
This directly contradicts our macroscopic observation that the world is unfair,
and hence we refute this assumption.
Principle of Indifference
The principle that replaces the fundamental assumption
is the Principle of Indifference.
It states that while the government and the CIA
work very hard to conceal the truth,
and we are almost unable to distinguish between microstates,
there is a fundamental difference between every state,
and every state is unique in its own way.
There is really no big implication that directly stems from this principle,
as we cannot make any observations that distinguish between
the fundamental assumption and this principle.
Hence, it is named the Principle of Indifference,
as we are completely ignorant and indifferent about this fact.
However, this principle leads to larger facts
that we will discuss in the following sections.
Wokeness
The measure of wokeness is a metric
that characterizes this uniqueness of a single state.
Assuming that a particle has some discrete energy states,
to balance out the fengshui of the overall system,
some states are more likely to be found than others.
This probability is described by the measure of wokeness $W$,
which is an experimentally determined quantity.
Determining the wokeness of a particle is currently a very tedious task,
as a physicist needs to manually interact with the particle,
ask them about their day,
provide them with a comfortable environment,
before probing them for their wokeness.
Also, wokeness of a particle can change at a moment’s notice,
partically when exchanging between systems,
so experimentally determining the wokeness of a particle
in their natural habitat is currently considered an impossible task.
We presume that wokeness is an exponental scale,
and therefore isn’t always an easy number to work with.
Therefore, we define litness of a state $\Lambda = \ln(W)$,
which is a much better metric to work with.
Both litness and wokeness are dimensionless quantities.
Rule of At Least Two
What interests researchers about the measure of litness is that
in every system, there is a threshold litness
that only allows particles above that limit to be counted.
The general rule of thumb is that
if a particle’s litness is within 2 of the maximum litess,
it will contribute to the probability of the system.
However, this fluctuates with the temperature and energy of the system,
and will become the Rule of At Least Three
when the system gets even hotter.
The particles that do not make this cut
are generally considered to be “cancelled”.
The state of cancellation is considered by current CBT researchers
as a wide field of study with huge undiscovered potential.
We do not know how particles physically recover from being cancelled,
but there has been initial evidence that
their litness will never recover to their previous maximum.
Evidence
The ideas of wokeness, litness, and cancellation
lie very central to the modern society’s ideals,
and are very politically correct,
which reinforces the truth within this theory.
While we do not have solid evidence,
we believe that in order for a theory to be widely accepted,
there will always be a need for an initial believer,
one that has complete faith in the ideas.
Furthermore, as this theory is mostly politically correct,
unlike modern day science,
we are less divisive and controversial,
which makes our theory more easily accessible to the common folk.
We hope you enjoy our short introduction to this new theory,
and will be willing to support us (financially) in future research.
A friend recently asked me,
“Boris, are you a mirror?
When I talk to you I feel like I’m talking to myself.”
I thought for a moment and tried to reply,
“Well, I dunno.
If you think I’m a mirror then I might just be a mirror.”
That apparently wasn’t a satisfactory answer,
and prompted them to elaborate
and try to convince my existence as a reflective coating of aluminium.
Which led me to think of the age-old philosophical question:
What am I? How do I know?
The only plausible explanation for me is that,
like a lot of things in science,
is that we don’t know.
We cannot know, in fact,
since we live in our own heads,
and in a sense,
we never get to experience ourselves outside of our own perception.
Maybe that is why only others can determine who you really are;
on the other hand, you could also say only you know yourself the best,
since the others have never lived inside your head.
Maybe the being that is presented outside
is not the same person as the one who’s inside your head.
Sometimes when I am in a large voice call,
people have told me that they will forget that I am there,
even if I occasionally unmute my mic.
I have been told that I often speak in short bursts,
and a lot of the times my words coincide with other people’s thoughts,
and I sound like their subconscious.
But again,
I only ever talk to my own subconscious;
I have never held a conversation with my “real” self.
I don’t think I sound like my subconsciousness at all.
If there were similarities between me and your subconsciousness,
I would like to apologize on behalf on them
for being quite the annoying voice.
Sometimes I sing in the shower. I can sometimes hear the echo when I hit particular notes.
The lowest note that I can sing, while simultaneously able to hear the reverbations is an A, 220Hz. We can model the shower room as an open-closed tube, in which resonant frequencies can be determined from the equation $f = \frac{nv}{4L}$, where $n$ is an odd number, $v$ is the speed of sound, and $L$ is length of tube. We know that the temperature inside the shower room is slightly higher than 25°C, so the speed of sound is expected to be slightly higher than 343m/s.
We can rearrange the equation to get $v = \frac{4fL}{n}$. Knowing that the glass panels that make up the shower room walls are 78” tall, we can convert that back to metric and say L = 1.98m. Plugging in n = 5 will obtain us a value of 348.5m/s.
From the textbook University Physics I found on OpenStax, equation 17.3.7 states that the speed of sound of air at sea level is about $v = 331 \sqrt{\frac{T}{273}}$, where T is temperature in Kelvins. Rearranging the equation gives us $T = 273 (\frac{v}{331})^2$, which evaluates to 303K = 30°C.
Now I know the ambient temperature of the shower room without using a thermometer, even though bringing in a thermometer is clearly a lot quicker.
As an enjoyer of different genres of music, I would like share with you a very satisfying chord progression that never fails to amaze me whenever I listen to it.
Note: Due to the lack of HTML support for the half-sharp/flat symbols, I will be using ½♯ & ½♭ to denote them.
Some Theory
In classical music theory, a very common musical cadence is the ii-V-I, where chords traverse counterclockwise two steps to the tonic chord. This brings the listener a sense of closure, a sense of “home”. In the diagram below, given the key of C major, we would travel Dmin-G(7)-C; in the key of A major, Bmin-E(7)-A; you get it.
Another way of providing harmonic motion, or traversing the circle of fifths, is to use chromaticism. By moving to neighbouring tones, one is making a large leap on the circle of fifths.
The Progression
The music I want to share with you is Sevish’s Gleam, which is an electronic piece that uses 22-tone equal temperament and a 5/4 beat.
Western classical music currently divides the octave into 12 steps; Gleam here divides it into 22. This allows us to get almost double the notes in an octave, with notes that can “fill in the gap” between semitones.
Said chord progression starts at 0:54. The idea is very simple: a descending chromatic, leaving the listener wondering where the destination is, and then hitting them with a V-I to signify arrival. However, as mentioned above, with the use of 22-TET, chromatic scales can mean descending in almost quarter tones.
Coupled with an ascending chromatic line above, we get a peculiar soundscape that is rarely heard: C½♯min - C9(omit7) - B½♯(½♯9) - B - B½♭7(♯9) - E - B♭7 - A(♯11). I have bolded the chords that follow the classical ii-V-I motion: they act as a reminder to the listener, bringing a tinge of familiarity as to not make 22-TET completely alien.
Conclusion
Yeah, nothing much. This is just cool. I’m nerding out.
Now that we’ve got an idea of what I have been doing in the past few months, let us dive deep into the process of this project, from the conception of the idea, to the completed paper on the previous post.
The Idea
Not long after we finished our term 1 projects, we were tasked with finding a topic of research/measurement for our term 2 projects. If you have read my posts here, you would know that I spent my Christmas break playing Minecraft instead.
About a week before we had to submit our topics for scrutiny, I sat down and realized that I had to either find a partner who already has an idea, or come up with an original one myself. Of course the former would be preferable, since I would save time by not needing to brainstorm; but after sifting through all the available proposals, it was either that I was not interested enough in the topic, or they already have found a partner.
I needed to find a topic that is physics/math related, and preferably easy data taking, because I did not want to go outdoors. I looked around my room, and after a solid minute, landed my sights on my Rubik’s cube, which I have not touched in the past 5 years. A project idea that is unconventional, all code-based; modelling and measuring the solves of a Rubik’s cube.
Getting a partner on board with the idea was relatively easy. Callum, being a fellow cuber, hardly needed any convincing. All that was left was to plan out our project, and execute that plan.
The Metric
The premise of our project was to measure the speed of different solving methods, taking into account human factors. But first, we have to find a way to measure this speed, because every human is different, and we have to somehow standardize a time-unit for moves.
The most obvious move is to start with pre-existing measurement systems. The common ones include the quarter-, half-, and slice-turn metrics. Out of the three, the quarter-turn metric is the most unrealistic one when measuring speed, since we know cubers tend to move fluidly. We also know, from “rigourous” testing, that slice turns are slightly slower than face turns, but do not take more than double the time. Since HTM treats slice turns as 2, and STM treats them as 1, we know that STM will inherently favour methods that utilize slice turns, while HTM will favour otherwise. However, to avoid working with decimals in code, we have decided to stick with these two metrics rather than to come up with one that treats slice turns as something between 1 & 2.
No matter how sophisticated counting slice turns are, they unfortunately do not take into account any other huamn-related factor. This leads to the incorporation of the 4 different factors: deduction, regrips, rotations, and look time. As explained in the previous post, the two different adjustments that we made to these pre-existing metrics are a combination of the those 4 factors.
The Code
Now, if you are reading this far into the post, this is most likely the part that you have been waiting for. The published version of code can be found here.
The Basics
Before a computer can solve cubes, first we need to have a cube. There are a few ways to model a cube in code, such as location-based (i.e. given a list of positions, what are the colours/pieces) and address-based (i.e. given a list of pieces, what are their positions). This will change how turning the faces will be coded. Since these moves are essentially functions that operate on positions, we have taken the former approach, and encoded all the information in 3 arrays: the 8 corners, 12 edges, and 6 centres.
Corner
1
2
3
4
5
6
7
8
Occupied by
White-green-orange
Yellow-orange-green
Yellow-blue-orange
White-red-green
White-orange-blue
Yellow-red-blue
Yellow-green-red
White-blue-red
Spin
2
2
1
1
0
1
0
2
You might be wondering why not 6 arrays, representing the 6 faces of the cube, or even a bitmap-style. Considering later that we have to work not only with colours, but also orientation of cubies, although maybe a single string of length 54 would be more memory efficient, the ease of working with the 3 arrays trumps any sort of efficiency that a colour approach allows.
Two enumerations are needed to assist with this approach. Encoding the edges and corners as a specific orientation of 2 and 3 colours respectively, these enumerations can be immediately slotted into our position and orientation arrays, such that one will determine the location of a cubie, while the other array (of a primitive data type) helps with determining its rotation.
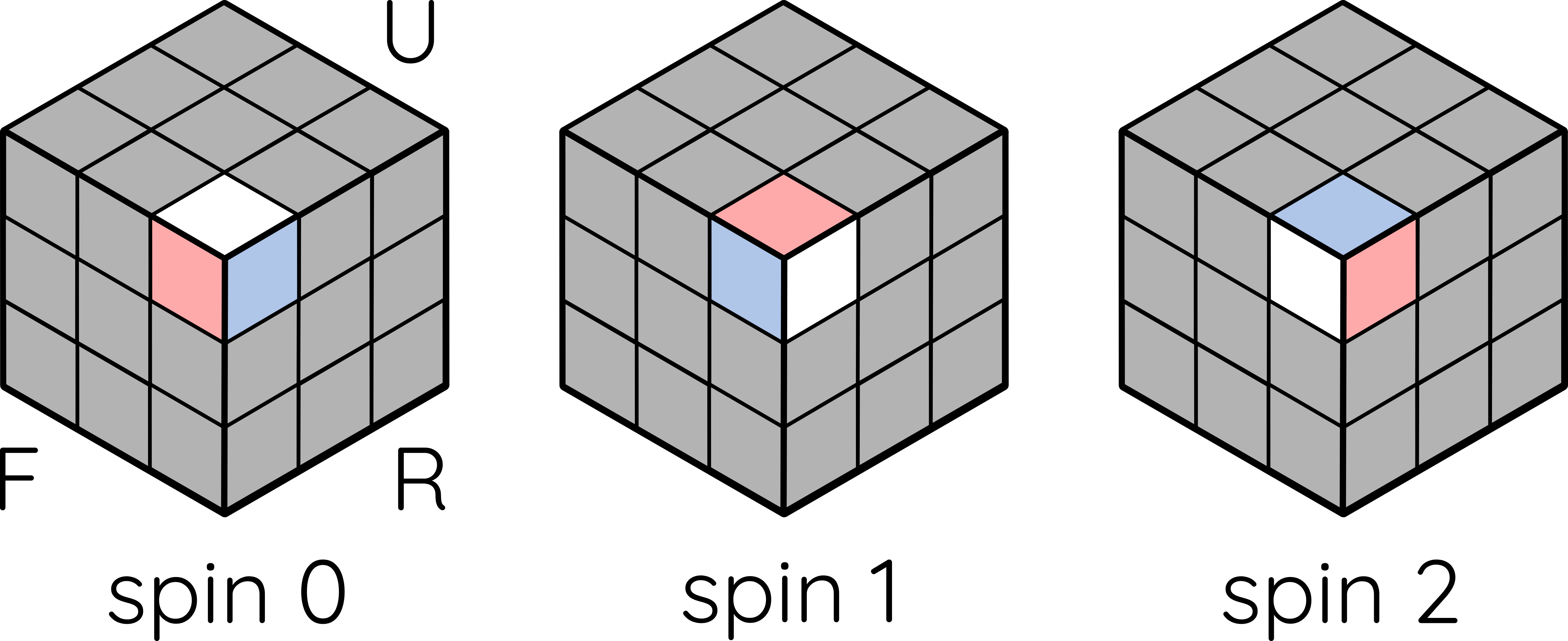
A series of definitions need to be made. In an homage to physics, the orientation properties of corners and edges are named spin and parity respectively. Instead of half spins in physics, a corner has 3 spin states: when its white/yellow face is facing top/bottom, spin is 0. Twisting it clockwise once gives spin 1; twice, spin 2.
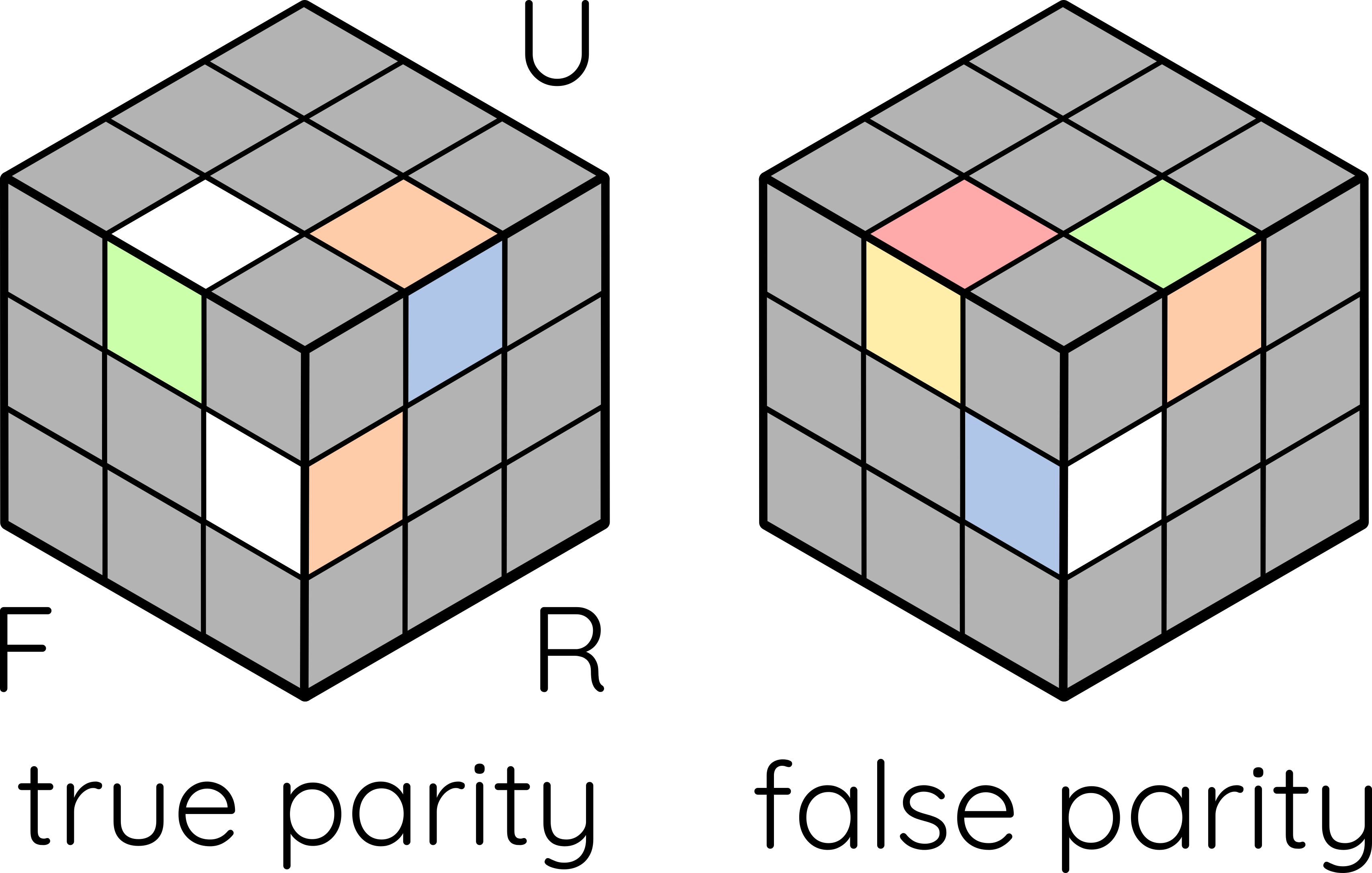
Parity is a little bit more complicated. Each edge has two faces, and we have to designate one as the “principal face”: if an edge has a white/yellow face, then that face is principal; if not, then the red/orange face will be principal. When an edge is in the top/bottom layer, parity is true when the principal face is facing top/bottom, false if not; if an edge is in the equatorial layer, then parity is true when the principal face is facing the front/back, false if facing the sides.
You will later see how these definitions of spin and parity help us identify cases and systematically solve the cube. But its first application is turning a single face: 4 edges and 4 corners will cycle, and 4 parities and spins will change. Note that while we could have coded it such that orientations will always follow the cubie instead of the location, linking it to the location is, again, efficient for case identification.
CFOP
I have to say straight out of the gate, that all intuitive steps in solving the cube were done algorithmically. I did not have time to write a search algorithm, and therefore all intuitive steps were not optimized. I am very sorry.
The white cross was inserted corner by corner, and on average it takes about 11 moves, significantly more than the 6 moves that if we were inserting intuitively. The error was taken into account when analyzing the data.
However, it is much easier to execute algorithmic steps using code. Every step is split into 3 substeps: obtainment (of information), identification (of case), and execution (of algorithm). As I am still a beginner at Java, the code is particularly messy in the beginning.
There are only 4 things that we needed to obtain to complete a single F2L pair: the positions & orientations of said corner & edge pair. While there are many F2L algorithms out there on the internet, we realized that they only work when said pair is either in position or in the top layer. This adds a layer of complexity, as we needed to identify whether “extraction” is needed to move all the needed pieces to the top layer. But after extracting the material, there are simply 42 cases in the decision tree, and an algorithm is fed into the code for it to choose.
OLL is a little bit more curious. In cuber terms, this step correctly orients all of the top layer; similarly in code, this step makes the entire cube spin 0 and true parity. The information we needed was the 8 orientations of the top layer. However, this time, the decision tree for case identification is a lot more complicated, as the computer cannot intuitively identify P-, W-, awkward cases, et cetera. Much time was spent on planning, as correctly identifying every feature for similar cases was difficult for the human eye.
After the fiasco that is the 57 cases of OLL, PLL is relatively easy. Only the 8 positions are considered, and to a certain extent, this is similar to identifying F2L cases. There is nothing too special about this step.
Roux
As I have said earlier, intuitive steps are not optimized. Due to constraints in time, F2B is completed using white cross and F2L algorithms.
The third step of Roux is to orient and permute corners of the top layer. A similar approach as OLL & PLL is taken, but this time using CMLL algorithms.
L6E is slightly different. It is considered a “semi-intuitive” step, so while EOLR can be partly executed using our parity and position information, actually inserting LR and finishing the middle slice permutation requires detailing of all four cases.
Regrips
3 out of the 4 factors that we keep track of are simple counters. However, regrips are a little bit difficult to quantify. To solve the problem, we simply simulate all the possible hand positions given a set of moves, and when there is an inevitable change in hand position, then a regrip must exist. Since with some moves, there is a multitude of hand positions possible; with that, in another nod to physics, we say that you are in a superposition, a combination of possible hand positions represented in arrays, until we get more specifics, and it collapses back to a single possible hand position.
Scrambles
While there are existing official computer program scramblers, none of them spit the scrambles out nicely in a single text file. So, I wrote a small file that generates a random length, random (with some constraints) move sequence. With that, the program can read the scrambles line by line and use the solvers that we spent so much time on.
Putting It All Together
Once the 10 weeks of painful coding was over, data taking was relatively simple, as predicted initially. We tested multiple numbers of scrambles & solves, and found out pretty quickly that our code was relatively efficient. We settled on 1 million solves as our data set, as data taking at that point takes less than 3 minutes. Also, we did not want to exceed to Microsoft Excel row limit, because otherwise we would have to write our own analysis software, which meant more coding, which implies more work and… 1 million solves was ideal.
I was pretty surprised that the graphs turned out to be pretty nice, and the normal curves looked pretty continuous for a discrete data set.
Final Thoughts
In the forseeable future (summer), I would like to revisit the No-Regrips factor, maybe add more methods, probably add a UI for completeness’ sake, and of course, make a third update after all of that is done.
Overall, coding this project was pretty fun. I would like the extend a token of thanks to:
Callum Lehingrat, without whom this project will not be complete;
Gwen Kornak, who provided much needed help with Java; and
all of Science One, who supported us throughout.
Thank you very much for reading all of this. Stay tuned for more updates.